It is generally used for market basket analysis and support to learn the products that can be purchased together. Mining positive and negative association rules from interesting frequent and infrequent itemsets. Hadoop is a large-scale distributed framework for parallel processing of big data. Figure6 presents the number of rules (positive as well as negative) at different minimum support levels. It is characterized as a level-wise search algorithm using antimonotonicity of itemsets. Ian H. Witten, Mark A. In: Proc. Brin et al. Association rules are purely descriptive: they present a summary of the relationship between the attributes, as manifested in the instances in the existing data set. It implements quicker execution than Apriori Algorithm. In many situations we would like to obtain a certain number of rulessay 50with the greatest possible coverage at a prespecified minimum accuracy level. The followed process and the implemented system offer an efficient and effective tool in the management of diabetes. Dr. Bagui has worked on funded as well unfunded research projects and has over 45 peer reviewed publications. In MapReduce job 3, the confidence and lift are calculated for the frequent 2-itemsets to determine the positive as well as negative association rules. The association rules were generated from the selected negative itemsets. The number of slave nodes was kept constant at 25. ACM Trans Inf Syst. also holds, because it has the same coverage as the original rule, and its accuracy must be at least as high as the original rules because the number of high-humidity, nonwindy, nonplaying days is necessarily less than that of nonwindy, nonplaying dayswhich makes the accuracy greater. 2005;7(2):15878. Total_count is then compared with min_supp and those equal to or above the min_supp threshold will be kept as the frequent 2-itemset. Web mining can be viewed as the application of adapted data mining methods to the internet, although data mining is defined as the application of the algorithm to discover patterns on mostly structured data fixed into a knowledge discovery process. Block size is a unit of work in Hadoops file system. In MapReduce, the combiner is an optimization function that reduces the amount of data shuffled between the mappers and reducers. Proc Very Large Data Bases. In addition, the rule may contain information about the frequency with which the attribute values are associated with each other. It can be used in the healthcare area to discover drug reactions for patients. Keeping the master node constant at 1, the number of slave nodes were varied from 5 to 25 at increments of 5. Association rules (Pang-Ning et al., 2006) are usually represented in the form X Y, where X (also called rule antecedent) and Y (also called rule consequent) are disjoint itemsets (ie, disjoint conjunctions of features). In our Hadoop implementation of the Apriori algorithm, first the algorithm is used to discover frequent itemsets. Still, this amounts to selecting a subset of descriptive rules which may be smaller but with no more predictive power than the full set of rules. eCollection 2014. The dataset contains 1,692,082 transactions with 5,267,656 distinct items. In the following sections we present terminology and equations commonly associated with association rule mining. 2004;22(3):381405. The frequent 1-itemset is read in from the distributed cache. b Number of negative association rules. In the asset management example, it could be used to discover the rules between different assets and their properties so that, for example, when there are assets missing in the GIS, it could be possible to infer what they might be. Furthermore, to rank the most interesting rules, the lift index is also used to measure the (symmetric) correlation between antecedent and consequent of the extracted rules. Liu X, Tao L, Cao K, Wang Z, Chen D, Guo J, Zhu H, Yang X, Wang Y, Wang J, Wang C, Liu L, Guo X. BMC Public Health. The frequent 1-itemset and their respective support values are then written to distributed cache. 2012. We use cookies to help provide and enhance our service and tailor content and ads. Paralleling the first MapReduce job, the 2-item (key, value) pairs are generated in the map phase. [29] presented an elaborate review of ARM applications and discussed the different aspects of the association rules that are used to extract the interesting patterns and relationships among the set of items in data repositories.
Rule confidence is the conditional probability of finding Y given X. doi: 10.1371/journal.pone.0092199. The output from MapReduce job 2 (frequent 2-itemsets) is read into MapReduce job 3 from the distributed cache. Both authors participated in the write-up of the paper. A similar method is described in [34]. In practice, the amount of computation needed to generate association rules depends critically on the minimum coverage specified. Google Scholar. 2004. It describes the strength of the implication and is given by c(X Y) = s(X Y)/s(X). Positive association rule mining finds items that are positively related to one another, that is, if one item goes up, the related item also goes up. In: Proc. In a supermarket, in the entire day processing, there may be several transactions committed. What is IrDA (Infrared Data Association)? Let the set of frequent itemsets of size k be Fk and their candidates be Ck. What is Q-learning with respect to reinforcement learning in Machine Learning? In: Computer2009, Bangalore, India, 2009. p. 14. This algorithm needs a breadth-first search and hash tree to compute the itemset efficiently. Ghemawat S, Gobioff H, Leung S. The Google file system. In: 2016 international conference on inventive computation technologies (ICICT). These rules however say nothing conclusive about the relationships between attributes in the instances that are not part of the given data set. Figure2 presents our Hadoop implementation of the Apriori algorithm diagramatically. Then the itemsets are checked against a minimum confidence level to determine the association rules.
The maximal length of a single transaction is 71,472. Also, association rules are not intended to be used together as a set, as classification rules are. The support is the number of transactions that include all items in the antecedent and consequent parts of the rule. Aggrawal and Yu [1, 2] claim that this model has good computational efficiency. The value of collective strengths range from 0 to , where 0 means that the items are perfectly negatively correlated and means the items are perfectly positively correlated. Mr. Dhars research interest includes data mining, Big data and database. Efficient algorithms such as Apriori (Agrawal and Srikant, 1994) and Eclat (Zaki, 2000) can find all frequent itemsets. Sally I. McClean, in Encyclopedia of Physical Science and Technology (Third Edition), 2003, An Association Rule associates the values of a given set of attributes with the value of another attribute from outside that set. The rest of the paper is organized as follows. Cornelis C, Yan P, Zhang X, Chen G. Mining positive and negative association rules from large databases. Few works have also been done on negative association rule mining [8, 15, 16, 21, 23, 25, 28], but none have been done in the big data framework. The confidence is the ratio of the number of transactions that include all items in the consequent as well as the antecedent (the support) to the number of transactions that include all items in the antecedent: confidence(X Y) = support(X Y) / support(X). 2015. In: Frequent pattern mining. We performed experiments that showed that, for this dataset, there were more negative association rules than positive association rules, so if we mine just for positive association rules, we could be losing some information. So, construct 's conditional pattern base first and then 's conditional FP _Tree Tree. Consider two item-sets 'X' and 'Y', if each item of 'X' is in 'Y', but there is at least one item of 'Y', that is not in 'X' then 'Y' is not a proper super-item set of 'X'. Finding all frequent itemsets in a data set is a complex procedure since it involves analyzing all possible itemsets. Once the frequent groups of items are found in a data set, it is also possible to discover the association rules that hold for the frequent itemsets. Reducers will output (item, total_count). The problem of identifying new, unexpected and interesting patterns in medical databases in general, and diabetic data repositories in specific, is considered in this paper. Total_count is compared with min_supp and those equal to or above the min_supp thresholdare kept as the frequent 1-itemset. Although the size of the power set grows exponentially in the number of items n in I, efficient search is possible using the downward-closure property of support (also called antimonotonicity) which guarantees that for a frequent itemset, all its subsets are also frequent, therefore for an infrequent itemset, all its supersets must also be infrequent. Figure8 presents the time required for different numbers of nodes for different data sizes (1.5GB, 6GB, 12GB, and 18GB) at a minimum support of 40% and minimum confidence of 85%. XY refers to X occurring in the absence of Y; XY refers to Y occurring in the absence of X; XY means not X and not Y. Lin X. MR-Apriori: association rules algorithm based on MapReduce, In: 2014 IEEE 5th international conference on software engineering and service science. Both authors read and approved the final manuscript. From Fig. Concrete items are items that have a high Chi-square value and exceeds the expected support. Positive association rule mining has been implemented in the MapReduce environment by many [4,18,19,20, 27]. Typically, a commercial data science tool offers association analysis in its tool package. Confidence measures the ratio of the number of entities in the database with the designated values of the attributes in both A and B to the number with the designated values of the attributes in A. The web has several aspects that yield multiple approaches for the mining process, such as web pages including text, web pages are connected via hyperlinks, and user activity can be monitored via web server logs. In: 5th international conference on computer science and education, Hefei, China, 2018. p. 14036. The Type C instance was chosen because this is a compute optimized type instance in AWS. IEEE Trans Knowl Data Eng. The itemsets X and Y are called antecedent and consequent of the rule, respectively. 2012. p. 6505. Gates A, Natkovich O, Chopra S, Kamath P, Narayanam S, Olston C, Reed B, Srinivasan S, Srivastava U. https://doi.org/10.1186/s40537-019-0238-8, DOI: https://doi.org/10.1186/s40537-019-0238-8. Traditional association rule mining algorithms, like Apriori, mostly mine positive association rules. The effects on run-time were recorded. ScienceDirect is a registered trademark of Elsevier B.V. ScienceDirect is a registered trademark of Elsevier B.V. University of Technology Sydney, Sydney, Australia, i hc Cng ngh Thnh ph H Ch Minh, Ho Chi Minh City, Viet Nam, An introduction to data mining in social networks, Advanced Data Mining Tools and Methods for Social Computing, in 1996, is an important data mining model. 2016;7(3):1517. Association rules are often used in situations where attributes are binaryeither present or absentand most of the attribute values associated with a given instance are absent. The process of generating the frequent itemsets calls for repeated full scans of the database, and in this era of big data, this is a major challenge of this algorithm. They used a correlation matrix to determine the relationships, positive as well as negative. Sourav De, Siddhartha Bhattacharyya, in Advanced Data Mining Tools and Methods for Social Computing, 2022. In: 2012 13th ACIS international conference on software engineering, artificial intelligence, networking and parallel/distributed computing. Web mining has a distinctive property to support a collection of multiple data types. This work has been partially supported by the Askew Institute of the University of West Florida. Before An itemset is said to be frequent, if X's support is no less than a minimum support threshold. For example, it is necessary to generate 280 candidate itemsets to obtain frequent itemsets of size 80. Files in HDFS are replicated, hence data stores in HDFS are fault tolerant. Savasere et al.s [26] approach to finding negative association rules was by combining positive frequent itemsets with domain knowledge in the form of a taxonomy. Number of frequent rules for different minimum supports. 2016. Stay ahead of the curve with Techopedia! For positive association rules we will use Definition 6 and for negative association rules we will use Definition 7. 2015 Apr 22;15:412. doi: 10.1186/s12889-015-1747-9. of ICDE. In a large data set it may be necessary to consider which rules are interesting to the user. By using this website, you agree with our Cookies Policy. Hence, an association rule is of the form: XY, where XI, YI and X Y=. [22] presented an implementation of Lift in the Big Data environment, but used the standard approach that is used in Aprioris sequential implementation. Department of Computer Science, University of West Florida, Pensacola, FL, 32514, USA, You can also search for this author in Association rule-mining is usually a data mining approach used to explore and interpret large transactional datasets to identify unique patterns and rules. This algorithm needs a depth-first search method to discover frequent itemsets in a transaction database. Lin M-Y, Lee P-Y, Hsueh S-C. Apriori-based frequent itemset mining algorithms on MapReduce. In our implementation, we use the support, confidence, and lift framework to determine positive as well as negative association rules using frequent itemset mining. 2009;150:574-8. This section presents the dataset and system parameters used for this study. The number of MapReduce iterations will depend on the number of itemsets being generated. Li N, Zeng L, He Q. Terms of Use - Tech moves fast! Finding Association Rules can be computationally intensive, and essentially involves finding all of the covering attribute sets, A, and then testing whether the rule A implies B, for some attribute set B separate from A, holds with sufficient confidence. 1998. p. 1824. In: ICUIMC 12 Proceedings of the 6th international conference on ubiquitous information management and communication.  The frequent 2-itemset and their respective support values are then written to distributed cache. d Time with and without combiner (18GB). Given the fact that repeated scans of the dataset are needed in the Apriori algorithm, the parallel and distributed structure of Hadoop should be availed of in an optimized way for mining positive as well as negative association rules in big data using the Apriori algorithm. The effectiveness of the rule is measured on the basis of support and confidence. Han J, Kamber M. Data mining: concepts and techniques. Time required for different number of slave nodes for different data sizes. We make use of cookies to improve our user experience. 2012. Would you like email updates of new search results? Association rules are no different from classification rules except that they can predict any attribute, not just the class, and this gives them the freedom to predict combinations of attributes too. In: Proceedings of ACM symposium on operating systems principles, Lake George, NY. Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations. Association rule mining can help to automatically discover regular patterns, associations, and correlations in the data. Agrawal R, Imielinski T, Swami A. In: Proc. From Fig. 7a, b we can see there were actually more negative rules generated than positive rules (except for minimum confidence of 75%). The support s(I) of an itemset I is the percentage of records containing I. Efficiency gains can be made by a combinatorial analysis of information gained from previous passes to eliminate unnecessary rules from the list of candidate rules. Cookies policy. [9] and [6] proposed a Chi-square test to find negative association rules. This is a case for the sparse data representation described in Section 2.4; the same algorithm for finding association rules applies.
The frequent 2-itemset and their respective support values are then written to distributed cache. d Time with and without combiner (18GB). Given the fact that repeated scans of the dataset are needed in the Apriori algorithm, the parallel and distributed structure of Hadoop should be availed of in an optimized way for mining positive as well as negative association rules in big data using the Apriori algorithm. The effectiveness of the rule is measured on the basis of support and confidence. Han J, Kamber M. Data mining: concepts and techniques. Time required for different number of slave nodes for different data sizes. We make use of cookies to improve our user experience. 2012. Would you like email updates of new search results? Association rules are no different from classification rules except that they can predict any attribute, not just the class, and this gives them the freedom to predict combinations of attributes too. In: Proceedings of ACM symposium on operating systems principles, Lake George, NY. Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations. Association rule mining can help to automatically discover regular patterns, associations, and correlations in the data. Agrawal R, Imielinski T, Swami A. In: Proc. From Fig. 7a, b we can see there were actually more negative rules generated than positive rules (except for minimum confidence of 75%). The support s(I) of an itemset I is the percentage of records containing I. Efficiency gains can be made by a combinatorial analysis of information gained from previous passes to eliminate unnecessary rules from the list of candidate rules. Cookies policy. [9] and [6] proposed a Chi-square test to find negative association rules. This is a case for the sparse data representation described in Section 2.4; the same algorithm for finding association rules applies.  By continuing you agree to the use of cookies. Mller H, Michoux N, Bandon D, Geissbuhler A. Int J Med Inform. The authors in [10] proposed a new Apriori-based algorithm (PNAR) that utilizes the upward closure property to find negative association rules. For this set of experiments, the original dataset of 1.5GB, 1 master node and 5 slave nodes, and the default block size of 64MBs was used. For example, rules concerning the associations found between items in a market basket analysis are supposed to reflect consumer behavior in general, and it was suggested that the discovered rules can guide business decisions such as the running of store promotions and new product placement in the store. If 'X' is closed and frequent, then it is called as. The mapper reads one transaction at a time and outputs a (key, value) pair where key is the item and value is 1, in the form (item, 1). All the possible itemsets is the power set over I and has size 2n1 (excluding the empty set which is not a valid itemset). The (key, value) pairs are then passed to the reduce phase. Bagui, S., Dhar, P.C. Provided by the Springer Nature SharedIt content-sharing initiative. Mining frequent patters is the basic task in all these cases. It describes the database in the form of a tree structure that is referred to as a frequent pattern or tree. A technique for mining negative association rules. Given a dataset D, a support threshold MinSup, and a confidence threshold MinConf, the mining process discovers all association rules with support and confidence greater than, or equal to, MinSup and MinConf, respectively. (1), as the probability of X and Y occurring together divided by the probability of X multiplied by the probability of Y [7, 14]. The accuracy has less influence because it does not affect the number of passes that must be made through the dataset. Management Association (Eds. The support for the Association Rule is simply the proportion of entities within the whole database that take the designated values of the attributes in A and B. The third MapReduce job is a map only operation. Teng et al.s [29, 30] work, referred to as substitution rule mining (SRM), discovers a subset of negative association rules. In, Transformative Open Access (Read & Publish), Healthcare Policy and Reform: Concepts, Methodologies, Tools, and Applications. After getting all the possible positive itemsets, some candidate negative itemsets were selected based on the taxonomy used. Singh S, Garg R, Mishra PK. By clicking sign up, you agree to receive emails from Techopedia and agree to our Terms of Use & Privacy Policy. Parallel implementation of Apriori algorithm based on MapReduce. 2022 BioMed Central Ltd unless otherwise stated. These are then used to find the frequent 2-itemsets. Moreover, association rule-mining is often referred to as market basket study, which is utilized to analyze habits in customer purchase. So these items are often complements or very related. The terminology, available in [14], commonly related to association rule mining is presented below: (Association rule) An association rule is stated in the form: XY, where XI, YI and X Y=. The .gov means its official. 7b presents the negative association rules at the various support and confidence levels. In the first MapReduce job, we determine the frequent 1-itemsets. \kern-0pt} {{\text{P}}\left( {\text{X}} \right){\text{P}}\left( {\text{Y}} \right)}}$$, $${\text{Supp }}\left( {\urcorner {\text{X}}} \right) = { 1 } - {\text{ Supp }}\left( {\text{X}} \right)$$, $${\text{Supp }}\left( {{\text{X}} \cup \urcorner {\text{Y}}} \right) = {\text{ Supp }}\left( {\text{X}} \right) - {\text{ Supp }}\left( {\text{X} \cup \text{Y}} \right)$$, $${\text{Conf }}({\text{X}} \Rightarrow \urcorner {\text{Y}}) = { 1 } - {\text{ Conf }}({\text{X}} \Rightarrow {\text{Y}})$$, $${\text{Supp }}\left( {\urcorner {\text{X} \cup \text{Y}}} \right) = {\text{ Supp }}\left( {\text{Y}} \right) - {\text{ Supp }}\left( {\text{Y} \cup \text{X}} \right)$$, $${\text{Conf }}(\urcorner {\text{X}} \Rightarrow {\text{Y}}) = \frac{{Supp \, \left( {\urcorner X \cup Y} \right)}}{{Supp \, \left( {\urcorner X} \right)}}$$, $${\text{Supp }}\left( {\urcorner {\text{X}} \cup \urcorner {\text{Y}}} \right) = { 1 } - {\text{ Supp }}\left( {\text{X}} \right) - {\text{ Supp }}\left( {\text{Y}} \right) \, + {\text{ Supp }}\left( {\text{X} \cup \text{Y}} \right)$$, $${\text{Conf }}\left( {\urcorner {\text{X}} \cup \urcorner {\text{Y}}} \right) = \frac{{Supp \, \left( {\urcorner X \cup \urcorner Y} \right)}}{{Supp \, \left( {\urcorner X} \right)}}$$, $${\text{C}}\left( {\text{I}} \right) \, = \frac{1 - v\left( I \right)}{{1 - E\left[ {v\left( I \right)} \right]}} \times \frac{{E\left[ {v\left( I \right)} \right]}}{v\left( I \right)}$$, $$\emptyset = \frac{{s\left( {XY} \right)s\left( {\urcorner X\urcorner Y} \right) - s\left( {X\urcorner Y} \right)s\left( {\urcorner XY} \right)}}{{\sqrt {\left( {s\left( X \right)s\left( {\urcorner Y} \right)s\left( Y \right)s\left( {\urcorner Y} \right)} \right)} }}$$, https://doi.org/10.1186/s40537-019-0238-8, http://creativecommons.org/licenses/by/4.0/.
By continuing you agree to the use of cookies. Mller H, Michoux N, Bandon D, Geissbuhler A. Int J Med Inform. The authors in [10] proposed a new Apriori-based algorithm (PNAR) that utilizes the upward closure property to find negative association rules. For this set of experiments, the original dataset of 1.5GB, 1 master node and 5 slave nodes, and the default block size of 64MBs was used. For example, rules concerning the associations found between items in a market basket analysis are supposed to reflect consumer behavior in general, and it was suggested that the discovered rules can guide business decisions such as the running of store promotions and new product placement in the store. If 'X' is closed and frequent, then it is called as. The mapper reads one transaction at a time and outputs a (key, value) pair where key is the item and value is 1, in the form (item, 1). All the possible itemsets is the power set over I and has size 2n1 (excluding the empty set which is not a valid itemset). The (key, value) pairs are then passed to the reduce phase. Bagui, S., Dhar, P.C. Provided by the Springer Nature SharedIt content-sharing initiative. Mining frequent patters is the basic task in all these cases. It describes the database in the form of a tree structure that is referred to as a frequent pattern or tree. A technique for mining negative association rules. Given a dataset D, a support threshold MinSup, and a confidence threshold MinConf, the mining process discovers all association rules with support and confidence greater than, or equal to, MinSup and MinConf, respectively. (1), as the probability of X and Y occurring together divided by the probability of X multiplied by the probability of Y [7, 14]. The accuracy has less influence because it does not affect the number of passes that must be made through the dataset. Management Association (Eds. The support for the Association Rule is simply the proportion of entities within the whole database that take the designated values of the attributes in A and B. The third MapReduce job is a map only operation. Teng et al.s [29, 30] work, referred to as substitution rule mining (SRM), discovers a subset of negative association rules. In, Transformative Open Access (Read & Publish), Healthcare Policy and Reform: Concepts, Methodologies, Tools, and Applications. After getting all the possible positive itemsets, some candidate negative itemsets were selected based on the taxonomy used. Singh S, Garg R, Mishra PK. By clicking sign up, you agree to receive emails from Techopedia and agree to our Terms of Use & Privacy Policy. Parallel implementation of Apriori algorithm based on MapReduce. 2022 BioMed Central Ltd unless otherwise stated. These are then used to find the frequent 2-itemsets. Moreover, association rule-mining is often referred to as market basket study, which is utilized to analyze habits in customer purchase. So these items are often complements or very related. The terminology, available in [14], commonly related to association rule mining is presented below: (Association rule) An association rule is stated in the form: XY, where XI, YI and X Y=. The .gov means its official. 7b presents the negative association rules at the various support and confidence levels. In the first MapReduce job, we determine the frequent 1-itemsets. \kern-0pt} {{\text{P}}\left( {\text{X}} \right){\text{P}}\left( {\text{Y}} \right)}}$$, $${\text{Supp }}\left( {\urcorner {\text{X}}} \right) = { 1 } - {\text{ Supp }}\left( {\text{X}} \right)$$, $${\text{Supp }}\left( {{\text{X}} \cup \urcorner {\text{Y}}} \right) = {\text{ Supp }}\left( {\text{X}} \right) - {\text{ Supp }}\left( {\text{X} \cup \text{Y}} \right)$$, $${\text{Conf }}({\text{X}} \Rightarrow \urcorner {\text{Y}}) = { 1 } - {\text{ Conf }}({\text{X}} \Rightarrow {\text{Y}})$$, $${\text{Supp }}\left( {\urcorner {\text{X} \cup \text{Y}}} \right) = {\text{ Supp }}\left( {\text{Y}} \right) - {\text{ Supp }}\left( {\text{Y} \cup \text{X}} \right)$$, $${\text{Conf }}(\urcorner {\text{X}} \Rightarrow {\text{Y}}) = \frac{{Supp \, \left( {\urcorner X \cup Y} \right)}}{{Supp \, \left( {\urcorner X} \right)}}$$, $${\text{Supp }}\left( {\urcorner {\text{X}} \cup \urcorner {\text{Y}}} \right) = { 1 } - {\text{ Supp }}\left( {\text{X}} \right) - {\text{ Supp }}\left( {\text{Y}} \right) \, + {\text{ Supp }}\left( {\text{X} \cup \text{Y}} \right)$$, $${\text{Conf }}\left( {\urcorner {\text{X}} \cup \urcorner {\text{Y}}} \right) = \frac{{Supp \, \left( {\urcorner X \cup \urcorner Y} \right)}}{{Supp \, \left( {\urcorner X} \right)}}$$, $${\text{C}}\left( {\text{I}} \right) \, = \frac{1 - v\left( I \right)}{{1 - E\left[ {v\left( I \right)} \right]}} \times \frac{{E\left[ {v\left( I \right)} \right]}}{v\left( I \right)}$$, $$\emptyset = \frac{{s\left( {XY} \right)s\left( {\urcorner X\urcorner Y} \right) - s\left( {X\urcorner Y} \right)s\left( {\urcorner XY} \right)}}{{\sqrt {\left( {s\left( X \right)s\left( {\urcorner Y} \right)s\left( Y \right)s\left( {\urcorner Y} \right)} \right)} }}$$, https://doi.org/10.1186/s40537-019-0238-8, http://creativecommons.org/licenses/by/4.0/.
Generate Ck+1, candidates of frequent itemsets of size k +1, from the frequent itemsets of size k. Scan the database and calculate the support of each candidate of frequent itemsets. Yuan X, Buckles BP, Yuan Z, Zhang J. Thank you for subscribing to our newsletter! Sometimes the dataset is too large to read in to main memory and must be kept on disk; then it may be worth reducing the number of passes by checking item sets of two consecutive sizes at the same time. What are the steps involved in Association Rule Clustering System? Reducers will output (item, total_count). Confidence of negative association rules will be in the form: Conf(XY)>min_conf; Conf(XY)>min_conf; Conf(XY)>min_conf. Rule quality is usually measured by rule support and confidence. If the confidence of (AB) is greater than the minimum confidence threshold and the lift of (AB) is greater than 1, than this is a positive association rule. 2014. Catalog design - the selection of items in a business catalog are often designed to complement each other so that buying one item will lead to buying of another. In the above example, only the first rule should be printed. J Pers Med. To find the frequent itemsets, first the set of frequent 1-itemsets are found by scanning the database and accumulating their counts. Editorial Review Policy. 6, 7a,b show that, in the context of big data, there are very few rules at confidence levels greater than 95% and support lower than 40%. 1994. p. 48799. Hadoop allows users to specify a combiner function to be run on the map output. 2001;13(6):86373. Discount is valid on purchases made directly through IGI Global Online Bookstore (, Sharma, Sugam. An approach to this is to use templates, to describe the form of interesting rules. Mining negative rules using GRD. The correlation coefficient for the association rule XY is: In this algorithm, positive and negative association rules are generated while calculating the correlation between each candidate itemset.
Techopedia is your go-to tech source for professional IT insight and inspiration. ARM, presented by Srikant et al. Domenico Talia, Fabrizio Marozzo, in Data Analysis in the Cloud, 2016. View Full Term. For example, if an itemset {mustard, Vienna sausages, buns} occurs in 25% of all transactions (1 out of 4 transactions), it has a support of 1/4 = 0.25. EWU Masters Thesis. 2006. p. 16. Silos. Dean J, Ghemawat S. MapReduce: simplified data processing on large clusters. In ARM, simple IF/THEN statements are the backbone of, Practical Machine Learning for Data Analysis Using Python. It assumes all data are categorical. 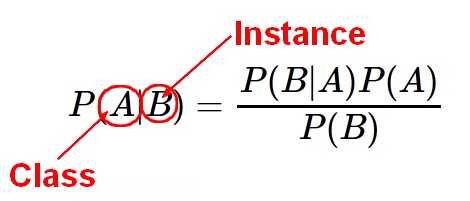 An itemset is frequent when its support is greater than, or equal to, a minimum support threshold MinSup. So keeping the coffee and sugar next to each other in store will be helpful to customers to buy the items together and improves sales of the company. Mining association rules between sets of items in large databases. How is it different from supervised and unsupervised learning? Blocks allow very large files to be split across and distributed over many machines at run time, allowing for more efficient distributed and parallel processing. In general, the Apriori algorithm gets good performance by reducing the size of candidate sets; however, when must be analyzed very many frequent itemsets, large itemsets, and/or very low minimum support is used, Apriori suffers from the cost of generating a huge number of candidate sets and for scanning all the transactions repeatedly to check a large set of candidate itemsets. Association rules that predict multiple consequences must be interpreted rather carefully. Thiruvady DR, Webb GI. An official website of the United States government. There is one master node and multiple slave nodes on each cluster. Wu et al.s [33] algorithm finds both the positive and negative association rules. PubMedGoogle Scholar. 10ad, we can see that all the runs with the combiner took less time. The most efficient block size of 256MB used the lowest number of mappers for all data sizes. Recent Advances and Emerging Applications in Text and Data Mining for Biomedical Discovery. Concaro S, Sacchi L, Cerra C, Bellazzi R. Stud Health Technol Inform. (Support) The support of a rule, s, in transaction set D, is the probability of X occurring in transaction set D. (Confidence) The confidence of a rule is the conditional probability that the subsequent Y is true given the predecessor X. Combiners are usually more helpful if the MapReduce jobs have limited bandwidth available on the cluster. 2004. p. 1615.
An itemset is frequent when its support is greater than, or equal to, a minimum support threshold MinSup. So keeping the coffee and sugar next to each other in store will be helpful to customers to buy the items together and improves sales of the company. Mining association rules between sets of items in large databases. How is it different from supervised and unsupervised learning? Blocks allow very large files to be split across and distributed over many machines at run time, allowing for more efficient distributed and parallel processing. In general, the Apriori algorithm gets good performance by reducing the size of candidate sets; however, when must be analyzed very many frequent itemsets, large itemsets, and/or very low minimum support is used, Apriori suffers from the cost of generating a huge number of candidate sets and for scanning all the transactions repeatedly to check a large set of candidate itemsets. Association rules that predict multiple consequences must be interpreted rather carefully. Thiruvady DR, Webb GI. An official website of the United States government. There is one master node and multiple slave nodes on each cluster. Wu et al.s [33] algorithm finds both the positive and negative association rules. PubMedGoogle Scholar. 10ad, we can see that all the runs with the combiner took less time. The most efficient block size of 256MB used the lowest number of mappers for all data sizes. Recent Advances and Emerging Applications in Text and Data Mining for Biomedical Discovery. Concaro S, Sacchi L, Cerra C, Bellazzi R. Stud Health Technol Inform. (Support) The support of a rule, s, in transaction set D, is the probability of X occurring in transaction set D. (Confidence) The confidence of a rule is the conditional probability that the subsequent Y is true given the predecessor X. Combiners are usually more helpful if the MapReduce jobs have limited bandwidth available on the cluster. 2004. p. 1615.