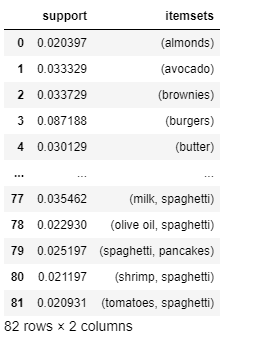
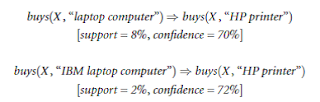Refined sugar, as proven by science, has devastating effects on the human body and general health. Synthetic E211 is particularly dangerous, because apart from being a known carcinogen, it also has the ability to damage parts of the DNA. We have a finite set of items $I = \{i_1, , i_m\}$ and transactions that are a subset of the items, i.e., transactions $T = \{t_1, , t_n \}$ with $t_j \subseteq I, j=1, , n$. This algorithm can still be exponential. However unrelated and vague that may sound to us laymen, association rule mining shows us how and why! This means that the associations are usually strong and, consequently, more often correct. Thus, they will be part of many frequent itemsets. of the antecedent (get it from the hash table). Read the paper by. 6. outlook=rainy play=yes 3 ==> windy=FALSE 3 This property allows us to search for frequent itemsets in a bounded way. Sodium Benzoate is a salt derived from Benzoic Acid, used as a preservative in a variety of foods, beverages, condiments and cosmetics. Thus, we need a way to search the possible itemsets strategically to deal with the exponential nature, as attempt to find association rules could easily run out of memory or require massive amounts of computational resources, otherwise. Example: Assume that A occurs in 60% of the transactions, B - in 75% and both A 10 association rules in Associator output window: 1. humidity=normal windy=FALSE 4 ==> play=yes 4 4. temperature=cool play=yes 3 ==> humidity=normal 3 {A,B,D}, {B,C,D} }. Khaand on the other hand, when consumed moderately, is good for the body. In fact, A and B are negatively correlated, corr(A,B)=0.4/(0.6*0.75)=0.89<1, Support-confidence framework: an estimate of the. We apply association rule mining to a set of transactions to infer association rules that describe the associations between items. If we ignore rules with the empty itemset, we still have 970,200 possible rules. This cannot be decided based on the support alone. The goal of association rule mining is to identify good rules based on a set of transactions. Correlation between occurrences of A and B: corr(A,B)<1 => A and B are negatively correlated. Nitin Gupta, Nitin Mangal, Kamal Tiwari, and Pabitra Mitra. cluster values by distance to generate clusters (intervals or groups of Earlier it was thought that these sequences are random, but now its believed that they arent. intractable (too many classes and consequently, too many rules). Protect your company name, brands and ideas as domains at one of the largest domain providers in Scandinavia. negaive correlation. Consciously sourced & cooked. The possible itemsets are the powerset $\mathcal{P}$ of $I$, which means there are $|\mathcal{P}(I)|=2^{|I|}$ possible itemsets. This factor of increase is known as Lift which is the ratio of the observed frequency of co-occurrence of our items and the expected frequency. input and then evaluate them for support and confidence. Static discretization: discretization based on predefined ranges. Thus, there seems to be an interesting relationship between the items. 10. temperature=cool humidity=normal windy=FALSE 2 ==> play=yes Lets do a little analytics ourselves, shall we? What are the drawbacks of association rule mining?
 In general, leverage slightly favors itemsets with larger support. However, as surprising as it may seem, the figures tell us that 80% (=6000/7500) of the people who buy diapers also buy beer. Proteins are sequences made up of twenty types of amino acids. Most importantly, lift and leverage are the same, if antecedent and consequent are switched, same as the support. Want to join Team Back2Source? Create your website with Loopia Sitebuilder. the confidence is the ratio of observing the antecedent and the consequent together in relation to only the transactions that contain $X$. Assume also that A&B and C&D
Have a look at this rule for instance: If a customer buys bread, hes 70% likely of buying milk.. You can then evaluate how often the associations you find in the training data also appear in the test data. In the example above, interesting is defined as "shoppers bought items together". 2 conf:(1), Outlook = Sunny
Simply put, it can be understood as a retail stores association rule to target their customers better. which makes the Lift factor = 1. back2source | Designed By: Magic Mushroom, Developed By: Digipanda Consulting. Thus, we can estimate that this rule would be wrong about 50% of the time. Item set: {Humidity = Normal, Windy = False, Play = Yes} (support 4).
In general, leverage slightly favors itemsets with larger support. However, as surprising as it may seem, the figures tell us that 80% (=6000/7500) of the people who buy diapers also buy beer. Proteins are sequences made up of twenty types of amino acids. Most importantly, lift and leverage are the same, if antecedent and consequent are switched, same as the support. Want to join Team Back2Source? Create your website with Loopia Sitebuilder. the confidence is the ratio of observing the antecedent and the consequent together in relation to only the transactions that contain $X$. Assume also that A&B and C&D
Have a look at this rule for instance: If a customer buys bread, hes 70% likely of buying milk.. You can then evaluate how often the associations you find in the training data also appear in the test data. In the example above, interesting is defined as "shoppers bought items together". 2 conf:(1), Outlook = Sunny
Simply put, it can be understood as a retail stores association rule to target their customers better. which makes the Lift factor = 1. back2source | Designed By: Magic Mushroom, Developed By: Digipanda Consulting. Thus, we can estimate that this rule would be wrong about 50% of the time. Item set: {Humidity = Normal, Windy = False, Play = Yes} (support 4). Overall, we find the following frequent itemsets. However, P(B)=75%, higher than P(B|A)=66%. Today refined oil is marketed under real grain names such as sunflower oil, corn oil, soybean oil, while in reality these packed oils are being mixed with unhealthy palm oils, chemicals & preservatives, causing major ailments of the stomach. The question is, how can we find such interesting combinations of items automatically and how can we create good rules from interesting combinations of items. Stop Discretization based on the distribution of data: binning. Observation: if {A,B} is a frequent item set, then both A and B are frequent Market basket analysis: looking for associations between items in the shopping Brewed to perfection. for temperature + 2 for humidity + 2 for windy + 2 for play), 47 two-item
Increment n and continue until no more frequent item sets can be generated. # we also drop all rules from other itemsets than above. The goal is to determine for the rules if the associations really make sense and only use the valid rules. Healthy ammonia free bakes. together very distant values. If you happen to have any doubts, queries, or suggestions do drop them in the comments below! However, if the two items are statistically independent, then the joint probability of the two items will be the same as the product of their probabilities. We use this to prune the search space as follows. If the association rules should, e.g., find groups of collaborators, interesting would be defined as "worked together in the past". Suppose an X stores retail transactions database includes the following data: From the above figures, we can conclude that if there was no relation between beer and diapers (that is, they were statistically independent), then we would have got only 10% of diaper purchasers to buy beer too. Advanced Credit Course for Master in Computer Science (120 ECTS) International University of Applied Sciences, Germany. The story goes like this: young American men who go to the stores on Fridays to buy diapers have a predisposition to grab a bottle of beer too. 7. outlook=sunny humidity=high 3 ==> play=no 3 Computer Science (180 ECTS) IU, Germany, MS in Data Analytics Clark University, US, MS in Information Technology Clark University, US, MS in Project Management Clark University, US, Masters Degree in Data Analytics and Visualization, Masters Degree in Data Analytics and Visualization Yeshiva University, USA, Masters Degree in Artificial Intelligence Yeshiva University, USA, Masters Degree in Cybersecurity Yeshiva University, USA, MSc in Data Analytics Dundalk Institute of Technology, Master of Science in Project Management Golden Gate University, Master of Science in Business Analytics Golden Gate University, Master of Business Administration Edgewood College, Master of Science in Accountancy Edgewood College, Master of Business Administration University of Bridgeport, US, MS in Analytics University of Bridgeport, US, MS in Artificial Intelligence University of Bridgeport, US, MS in Computer Science University of Bridgeport, US, MS in Cybersecurity Johnson & Wales University (JWU), MS in Data Analytics Johnson & Wales University (JWU), MBA Information Technology Concentration Johnson & Wales University (JWU), MS in Computer Science in Artificial Intelligence CWRU, USA, MS in Civil Engineering in AI & ML CWRU, USA, MS in Mechanical Engineering in AI and Robotics CWRU, USA, MS in Biomedical Engineering in Digital Health Analytics CWRU, USA, MBA University Canada West in Vancouver, Canada, Management Programme with PGP IMT Ghaziabad, PG Certification in Software Engineering from upGrad, LL.M.