However, Its main disadvantage is that it cant learn interactions between features.
 More specifically, Regression analysis helps us to understand how the value of the dependent variable is changing corresponding to an independent variable when other independent variables are held fixed. How about sharing with the world? The graph consists of a line that fits the data points. Heres an example of a decision tree, courtesy of Hackerearth. Probably you would have your mindset transitioned from the uncertainty parameter or a more certain one. For classification, the outputs would be discrete, while they would be continuous for regression. Now, lets look at some of the most prominent loss functions for classification. Ridge regression is a regularization technique, which is used to reduce the complexity of the model. All rights reserved. It will be an equidistant hyperplane with the points as close as possible. It uses the concept of threshold levels, values above the threshold level are rounded up to 1, and values below the threshold level are rounded up to 0. {
As for the actual differences, Classification trees are used for handling problems dealing with classification results, and Regression trees work with prediction type problems. It addresses the disadvantages of Mean Squared Error and Mean Absolute Error. Data labels and predictions consist of continuous nature. For the loss function, you cannot apply Mean Squared Error (MSE) used in linear regression here as the target variable P is non-linear. Random Forest Classification:Random forest processes many decision trees, each one predicting a value for target variable probability. A decision tree is constructed starting from the root node/parent node (dataset), which splits into left and right child nodes (subsets of dataset). "@type": "WebPage",
Machine Learning is one of the most trending buzzwords. Does the prediction have to be fast? Theyre prone to high variance: Even a tiny variance in data can lead to a high variance in the resulting prediction, creating an unstable outcome. You might have heard about the applications of weather forecasting, spam classification, or stock price prediction applications, so what exactly do these applications use? For example, to classify an email as spam or not spam, we can assign label 0 for spam and label 1 for not spam, which will likewise convert the output probabilities to either one of these labels, making it a binary classification problem. Our machines are getting more intelligent and more capable of independent tasks, and they owe it to the rapidly growing fields of Artificial Intelligence and Machine Learning. The graph comprises a decision boundary segregating the classes. Here we are discussing some important types of regression which are given below: Here, Y = dependent variables (target variables), To put it another, more straightforward way, classification algorithms predict an event occurrence probability by fitting data to a logit function. Classification and Regression, both being supervised algorithms, require labeled data for training. Please mail your requirement at [emailprotected] Duration: 1 week to 2 week. With uncertainty? Simple results:Its easy to observe and classify these results, making them easier to evaluate or explain to other people. In a decision tree for classification, the leaf nodes comprise binary values such as True, False, or Yes, No. The first node is called the root node. "name": "ProjectPro"
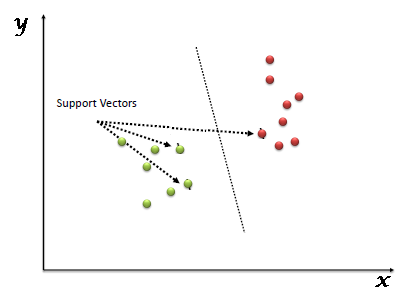
In such a scenario, we can say that impurity is present because the negative class is also present, and there is no clear split. It is also called as. In classification, the data comprises discrete labels or classes such as 0, 1, cat, dog, flower, bird, etc. Meanwhile, for a better decision, here is a checklist of the factors for you: To add to, one must pay attention to the complexity of the algorithm while choosing. The equation for ridge regression will be: A general linear or polynomial regression will fail if there is high collinearity between the independent variables, so to solve such problems, Ridge regression can be used. Some popular applications of linear regression are: When we provide the input values (data) to the function, it gives the S-curve as follows: There are three types of logistic regression: Support Vector Machine is a supervised learning algorithm which can be used for regression as well as classification problems. A Classification tree is an algorithm with either a fixed or categorical target variable. As MSE extremely penalizes large errors, RMSE can bring a better correlation between both variables. Here we are predicting the salary of an employee on the basis of. So, visit Simplilearn today and take those vital first steps! Each model will provide an output, and the final output will be decided based on the maximum votes obtained from voting. Here are the types of Regression algorithms commonly found in the Machine Learning field: And here are the types of Classification algorithms typically used in Machine Learning: This image, courtesy of Javatpoint, illustrates Classification versus Regression algorithms.
More specifically, Regression analysis helps us to understand how the value of the dependent variable is changing corresponding to an independent variable when other independent variables are held fixed. How about sharing with the world? The graph consists of a line that fits the data points. Heres an example of a decision tree, courtesy of Hackerearth. Probably you would have your mindset transitioned from the uncertainty parameter or a more certain one. For classification, the outputs would be discrete, while they would be continuous for regression. Now, lets look at some of the most prominent loss functions for classification. Ridge regression is a regularization technique, which is used to reduce the complexity of the model. All rights reserved. It will be an equidistant hyperplane with the points as close as possible. It uses the concept of threshold levels, values above the threshold level are rounded up to 1, and values below the threshold level are rounded up to 0. {
As for the actual differences, Classification trees are used for handling problems dealing with classification results, and Regression trees work with prediction type problems. It addresses the disadvantages of Mean Squared Error and Mean Absolute Error. Data labels and predictions consist of continuous nature. For the loss function, you cannot apply Mean Squared Error (MSE) used in linear regression here as the target variable P is non-linear. Random Forest Classification:Random forest processes many decision trees, each one predicting a value for target variable probability. A decision tree is constructed starting from the root node/parent node (dataset), which splits into left and right child nodes (subsets of dataset). "@type": "WebPage",
Machine Learning is one of the most trending buzzwords. Does the prediction have to be fast? Theyre prone to high variance: Even a tiny variance in data can lead to a high variance in the resulting prediction, creating an unstable outcome. You might have heard about the applications of weather forecasting, spam classification, or stock price prediction applications, so what exactly do these applications use? For example, to classify an email as spam or not spam, we can assign label 0 for spam and label 1 for not spam, which will likewise convert the output probabilities to either one of these labels, making it a binary classification problem. Our machines are getting more intelligent and more capable of independent tasks, and they owe it to the rapidly growing fields of Artificial Intelligence and Machine Learning. The graph comprises a decision boundary segregating the classes. Here we are discussing some important types of regression which are given below: Here, Y = dependent variables (target variables), To put it another, more straightforward way, classification algorithms predict an event occurrence probability by fitting data to a logit function. Classification and Regression, both being supervised algorithms, require labeled data for training. Please mail your requirement at [emailprotected] Duration: 1 week to 2 week. With uncertainty? Simple results:Its easy to observe and classify these results, making them easier to evaluate or explain to other people. In a decision tree for classification, the leaf nodes comprise binary values such as True, False, or Yes, No. The first node is called the root node. "name": "ProjectPro"
In such a scenario, we can say that impurity is present because the negative class is also present, and there is no clear split. It is also called as. In classification, the data comprises discrete labels or classes such as 0, 1, cat, dog, flower, bird, etc. Meanwhile, for a better decision, here is a checklist of the factors for you: To add to, one must pay attention to the complexity of the algorithm while choosing. The equation for ridge regression will be: A general linear or polynomial regression will fail if there is high collinearity between the independent variables, so to solve such problems, Ridge regression can be used. Some popular applications of linear regression are: When we provide the input values (data) to the function, it gives the S-curve as follows: There are three types of logistic regression: Support Vector Machine is a supervised learning algorithm which can be used for regression as well as classification problems. A Classification tree is an algorithm with either a fixed or categorical target variable. As MSE extremely penalizes large errors, RMSE can bring a better correlation between both variables. Here we are predicting the salary of an employee on the basis of. So, visit Simplilearn today and take those vital first steps! Each model will provide an output, and the final output will be decided based on the maximum votes obtained from voting. Here are the types of Regression algorithms commonly found in the Machine Learning field: And here are the types of Classification algorithms typically used in Machine Learning: This image, courtesy of Javatpoint, illustrates Classification versus Regression algorithms.  So for such case we need Regression analysis which is a statistical method and used in machine learning and data science. For regression, the nodes' values will comprise continuous numerical values instead of discrete binary choices. I Read More, Machine Learning is one of the most trending buzzwords. "https://daxg39y63pxwu.cloudfront.net/images/blog/classification-vs-regression-in-machine-learning/image_79934569531641926364489.png",
According to Andreybu, a German scientist with more than 5 years of the machine learning experience, If you can understand whether the machine learning task is a regression or classification problem then choosing the right algorithm is a piece of cake.. So, teach your data into the right algorithms, run them all in either parallel or serial, and at the end evaluate the performance of the algorithms to select the best one(s). It is similar to the Ridge Regression except that penalty term contains only the absolute weights instead of a square of weights. This is called Smooth Mean Absolute Error loss. Regression is a supervised learning technique which helps in finding the correlation between variables and enables us to predict the continuous output variable based on the one or more predictor variables. For example, if the response variable is something like the value of an object or todays temperature, we use a Regression tree. But, you do not code the Algorithm, and your focus should be on the data. },
Suppose we have the past labeled data on the weather of a place that labels individual days into three classes - sunny, cloudy, or rainy. Binary Classification: This classification problem can fall into two classes. "description": "“Machine Learning†is one of the most trending buzzwords. X= Independent variables (predictor variables), Principal Components Regression:This regression technique is widely used. We can understand the concept of regression analysis using the below example: Example: Suppose there is a marketing company A, who does various advertisement every year and get sales on that. More than 10,000 people enjoy reading, and you will love it too. Information gain measures the amount of entropy reduced for a particular node with respect to the parent node. The concept of decision trees for regression is quite analogous to the decision trees for classification. Furthermore, while converting the raw data to a polished one compliant to the models, one must take care of the following : Now that you have a clear picture of your data, you could implement proper tools to choose the right algorithm. To put it differently, you could use this for: Apparently, single trees are used rarely, but in composition, with many others, they build efficient algorithms such as Random Forest or Gradient Tree Boosting. This program features 58 hours of applied learning, interactive labs, four hands-on projects, and mentoring. Logistic regression is a type of regression, but it is different from the linear regression algorithm in the term how they are used. According to this case study, you need to tweak the features to get the labels. When using a Classification algorithm, a computer program gets taught on the training dataset and categorizes the data into various categories depending on what it learned. Random forest is built using, Classification Loss Functions vs. Regression Loss Functions. Mean Absolute Error / L1 is the sum of the absolute distance between the predicted and the target variable. It is used for solving the regression problem in machine learning. The output variable must be either continuous nature or real value. Below are some keywords which are used in Support Vector Regression: In SVR, we always try to determine a hyperplane with a maximum margin, so that maximum number of datapoints are covered in that margin. Similarly, the branching continues on the other features. We may earn affiliate commissions from buying links on this site. Like SVM, SVR also deals with predicting a hyperplane to suit all the points in data. In semantic tagging, the idea is to analyze some text information and predict the content categories of the text. This function works well with many classification problems and is most used in the industry. In case you want to optimize an objective function by interacting with an environment, its a. To understand that, lets first explore the concept of entropy. The top few nodes of the decision tree are the most important, so these decision trees automatically handle feature selection. As the output of logistic regression is a probability score, the sigmoid function is used to map the output between 0 and 1. On the other hand, Classification is an algorithm that finds functions that help divide the dataset into classes based on various parameters. This loss is used for multi-class classification problems. Downloadable solution code | Explanatory videos | Tech Support. This is an example of multi-class classification. This article explores Regression vs. So, do check out the awesome, AWS Project for Batch Processing with PySpark on AWS EMR, Image Classification Model using Transfer Learning in PyTorch, Build a Data Pipeline in AWS using NiFi, Spark, and ELK Stack, Learn to Build Regression Models with PySpark and Spark MLlib, NLP Project for Multi Class Text Classification using BERT Model, Build Customer Propensity to Purchase Model in Python, PySpark Project-Build a Data Pipeline using Hive and Cassandra, Project-Driven Approach to PySpark Partitioning Best Practices, PyCaret Project to Build and Deploy an ML App using Streamlit, Data Science and Machine Learning Projects, Hands-On Real Time PySpark Project for Beginners, Linear Regression Model Project in Python for Beginners Part 1, Build an Analytical Platform for eCommerce using AWS Services, Loan Eligibility Prediction using Gradient Boosting Classifier, PySpark ETL Project-Build a Data Pipeline using S3 and MySQL, end-to-end solved machine learning projects, Snowflake Data Warehouse Tutorial for Beginners with Examples, Jupyter Notebook Tutorial - A Complete Beginners Guide, Tableau Tutorial for Beginners -Step by Step Guide, MLOps Python Tutorial for Beginners -Get Started with MLOps, Alteryx Tutorial for Beginners to Master Alteryx in 2021, Free Microsoft Power BI Tutorial for Beginners with Examples, Theano Deep Learning Tutorial for Beginners, Computer Vision Tutorial for Beginners | Learn Computer Vision, Python Pandas Tutorial for Beginners - The A-Z Guide, Hadoop Online Tutorial Hadoop HDFS Commands Guide, MapReduce TutorialLearn to implement Hadoop WordCount Example, Hadoop Hive Tutorial-Usage of Hive Commands in HQL, Hive Tutorial-Getting Started with Hive Installation on Ubuntu, Learn Java for Hadoop Tutorial: Inheritance and Interfaces, Learn Java for Hadoop Tutorial: Classes and Objects, Apache Spark Tutorial - Run your First Spark Program, Best PySpark Tutorial for Beginners-Learn Spark with Python, R Tutorial- Learn Data Visualization with R using GGVIS, Performance Metrics for Machine Learning Algorithms, Step-by-Step Apache Spark Installation Tutorial, R Tutorial: Importing Data from Relational Database, Introduction to Machine Learning Tutorial, Machine Learning Tutorial: Linear Regression, Machine Learning Tutorial: Logistic Regression, Tutorial- Hadoop Multinode Cluster Setup on Ubuntu, Apache Pig Tutorial: User Defined Function Example, Apache Pig Tutorial Example: Web Log Server Analytics, Flume Hadoop Tutorial: Twitter Data Extraction, Flume Hadoop Tutorial: Website Log Aggregation, Hadoop Sqoop Tutorial: Example Data Export, Hadoop Sqoop Tutorial: Example of Data Aggregation, Apache Zookepeer Tutorial: Example of Watch Notification, Apache Zookepeer Tutorial: Centralized Configuration Management, Big Data Hadoop Tutorial for Beginners- Hadoop Installation, Explain the features of Amazon Personalize, Introduction to Amazon Personalize and its use cases, Explain the features of Amazon Nimble Studio, Introduction to Amazon Nimble Studio and its use cases, Introduction to Amazon Neptune and its use cases, Introduction to Amazon MQ and its use cases, Explain the features of Amazon Monitron for Redis, Introduction to Amazon Monitron and its use cases, Explain the features of Amazon MemoryDB for Redis, Introduction to Amazon MemoryDB for Redis and its use cases, Introduction to Amazon Managed Grafana and its use cases, Explain the features of Amazon Managed Blockchain, Walmart Sales Forecasting Data Science Project, Credit Card Fraud Detection Using Machine Learning, Resume Parser Python Project for Data Science, Retail Price Optimization Algorithm Machine Learning, Store Item Demand Forecasting Deep Learning Project, Handwritten Digit Recognition Code Project, Machine Learning Projects for Beginners with Source Code, Data Science Projects for Beginners with Source Code, Big Data Projects for Beginners with Source Code, IoT Projects for Beginners with Source Code, Data Science Interview Questions and Answers, Pandas Create New Column based on Multiple Condition, Optimize Logistic Regression Hyper Parameters, Drop Out Highly Correlated Features in Python, Convert Categorical Variable to Numeric Pandas, Evaluate Performance Metrics for Machine Learning Models. "@type": "Organization",
"dateModified": "2022-06-23"
Polynomial Regression is a type of regression which models the. ",
Deep Learning Course with Keras and TensorFlow Certification Training. In the equation, E(Y) refers to the entropy of parent node.
So for such case we need Regression analysis which is a statistical method and used in machine learning and data science. For regression, the nodes' values will comprise continuous numerical values instead of discrete binary choices. I Read More, Machine Learning is one of the most trending buzzwords. "https://daxg39y63pxwu.cloudfront.net/images/blog/classification-vs-regression-in-machine-learning/image_79934569531641926364489.png",
According to Andreybu, a German scientist with more than 5 years of the machine learning experience, If you can understand whether the machine learning task is a regression or classification problem then choosing the right algorithm is a piece of cake.. So, teach your data into the right algorithms, run them all in either parallel or serial, and at the end evaluate the performance of the algorithms to select the best one(s). It is similar to the Ridge Regression except that penalty term contains only the absolute weights instead of a square of weights. This is called Smooth Mean Absolute Error loss. Regression is a supervised learning technique which helps in finding the correlation between variables and enables us to predict the continuous output variable based on the one or more predictor variables. For example, if the response variable is something like the value of an object or todays temperature, we use a Regression tree. But, you do not code the Algorithm, and your focus should be on the data. },
Suppose we have the past labeled data on the weather of a place that labels individual days into three classes - sunny, cloudy, or rainy. Binary Classification: This classification problem can fall into two classes. "description": "“Machine Learning†is one of the most trending buzzwords. X= Independent variables (predictor variables), Principal Components Regression:This regression technique is widely used. We can understand the concept of regression analysis using the below example: Example: Suppose there is a marketing company A, who does various advertisement every year and get sales on that. More than 10,000 people enjoy reading, and you will love it too. Information gain measures the amount of entropy reduced for a particular node with respect to the parent node. The concept of decision trees for regression is quite analogous to the decision trees for classification. Furthermore, while converting the raw data to a polished one compliant to the models, one must take care of the following : Now that you have a clear picture of your data, you could implement proper tools to choose the right algorithm. To put it differently, you could use this for: Apparently, single trees are used rarely, but in composition, with many others, they build efficient algorithms such as Random Forest or Gradient Tree Boosting. This program features 58 hours of applied learning, interactive labs, four hands-on projects, and mentoring. Logistic regression is a type of regression, but it is different from the linear regression algorithm in the term how they are used. According to this case study, you need to tweak the features to get the labels. When using a Classification algorithm, a computer program gets taught on the training dataset and categorizes the data into various categories depending on what it learned. Random forest is built using, Classification Loss Functions vs. Regression Loss Functions. Mean Absolute Error / L1 is the sum of the absolute distance between the predicted and the target variable. It is used for solving the regression problem in machine learning. The output variable must be either continuous nature or real value. Below are some keywords which are used in Support Vector Regression: In SVR, we always try to determine a hyperplane with a maximum margin, so that maximum number of datapoints are covered in that margin. Similarly, the branching continues on the other features. We may earn affiliate commissions from buying links on this site. Like SVM, SVR also deals with predicting a hyperplane to suit all the points in data. In semantic tagging, the idea is to analyze some text information and predict the content categories of the text. This function works well with many classification problems and is most used in the industry. In case you want to optimize an objective function by interacting with an environment, its a. To understand that, lets first explore the concept of entropy. The top few nodes of the decision tree are the most important, so these decision trees automatically handle feature selection. As the output of logistic regression is a probability score, the sigmoid function is used to map the output between 0 and 1. On the other hand, Classification is an algorithm that finds functions that help divide the dataset into classes based on various parameters. This loss is used for multi-class classification problems. Downloadable solution code | Explanatory videos | Tech Support. This is an example of multi-class classification. This article explores Regression vs. So, do check out the awesome, AWS Project for Batch Processing with PySpark on AWS EMR, Image Classification Model using Transfer Learning in PyTorch, Build a Data Pipeline in AWS using NiFi, Spark, and ELK Stack, Learn to Build Regression Models with PySpark and Spark MLlib, NLP Project for Multi Class Text Classification using BERT Model, Build Customer Propensity to Purchase Model in Python, PySpark Project-Build a Data Pipeline using Hive and Cassandra, Project-Driven Approach to PySpark Partitioning Best Practices, PyCaret Project to Build and Deploy an ML App using Streamlit, Data Science and Machine Learning Projects, Hands-On Real Time PySpark Project for Beginners, Linear Regression Model Project in Python for Beginners Part 1, Build an Analytical Platform for eCommerce using AWS Services, Loan Eligibility Prediction using Gradient Boosting Classifier, PySpark ETL Project-Build a Data Pipeline using S3 and MySQL, end-to-end solved machine learning projects, Snowflake Data Warehouse Tutorial for Beginners with Examples, Jupyter Notebook Tutorial - A Complete Beginners Guide, Tableau Tutorial for Beginners -Step by Step Guide, MLOps Python Tutorial for Beginners -Get Started with MLOps, Alteryx Tutorial for Beginners to Master Alteryx in 2021, Free Microsoft Power BI Tutorial for Beginners with Examples, Theano Deep Learning Tutorial for Beginners, Computer Vision Tutorial for Beginners | Learn Computer Vision, Python Pandas Tutorial for Beginners - The A-Z Guide, Hadoop Online Tutorial Hadoop HDFS Commands Guide, MapReduce TutorialLearn to implement Hadoop WordCount Example, Hadoop Hive Tutorial-Usage of Hive Commands in HQL, Hive Tutorial-Getting Started with Hive Installation on Ubuntu, Learn Java for Hadoop Tutorial: Inheritance and Interfaces, Learn Java for Hadoop Tutorial: Classes and Objects, Apache Spark Tutorial - Run your First Spark Program, Best PySpark Tutorial for Beginners-Learn Spark with Python, R Tutorial- Learn Data Visualization with R using GGVIS, Performance Metrics for Machine Learning Algorithms, Step-by-Step Apache Spark Installation Tutorial, R Tutorial: Importing Data from Relational Database, Introduction to Machine Learning Tutorial, Machine Learning Tutorial: Linear Regression, Machine Learning Tutorial: Logistic Regression, Tutorial- Hadoop Multinode Cluster Setup on Ubuntu, Apache Pig Tutorial: User Defined Function Example, Apache Pig Tutorial Example: Web Log Server Analytics, Flume Hadoop Tutorial: Twitter Data Extraction, Flume Hadoop Tutorial: Website Log Aggregation, Hadoop Sqoop Tutorial: Example Data Export, Hadoop Sqoop Tutorial: Example of Data Aggregation, Apache Zookepeer Tutorial: Example of Watch Notification, Apache Zookepeer Tutorial: Centralized Configuration Management, Big Data Hadoop Tutorial for Beginners- Hadoop Installation, Explain the features of Amazon Personalize, Introduction to Amazon Personalize and its use cases, Explain the features of Amazon Nimble Studio, Introduction to Amazon Nimble Studio and its use cases, Introduction to Amazon Neptune and its use cases, Introduction to Amazon MQ and its use cases, Explain the features of Amazon Monitron for Redis, Introduction to Amazon Monitron and its use cases, Explain the features of Amazon MemoryDB for Redis, Introduction to Amazon MemoryDB for Redis and its use cases, Introduction to Amazon Managed Grafana and its use cases, Explain the features of Amazon Managed Blockchain, Walmart Sales Forecasting Data Science Project, Credit Card Fraud Detection Using Machine Learning, Resume Parser Python Project for Data Science, Retail Price Optimization Algorithm Machine Learning, Store Item Demand Forecasting Deep Learning Project, Handwritten Digit Recognition Code Project, Machine Learning Projects for Beginners with Source Code, Data Science Projects for Beginners with Source Code, Big Data Projects for Beginners with Source Code, IoT Projects for Beginners with Source Code, Data Science Interview Questions and Answers, Pandas Create New Column based on Multiple Condition, Optimize Logistic Regression Hyper Parameters, Drop Out Highly Correlated Features in Python, Convert Categorical Variable to Numeric Pandas, Evaluate Performance Metrics for Machine Learning Models. "@type": "Organization",
"dateModified": "2022-06-23"
Polynomial Regression is a type of regression which models the. ",
Deep Learning Course with Keras and TensorFlow Certification Training. In the equation, E(Y) refers to the entropy of parent node. Leo Breiman, Jerome Friedman, Richard Olshen, and Charles Stone introduced the Classification and Regression tree methodology in 1984. Classification algorithms find the mapping function to map the x input to y discrete output. These models are essentially individual decision trees. Fast-Track Your Career Transition with ProjectPro. They are built using Machine Learning algorithms. This table shows the specific differences between Regression vs. Semrush is an all-in-one digital marketing solution with more than 50 tools in SEO, social media, and content marketing. We use Classification trees when the dataset must be divided into classes that belong to the response variable. Prior to learning Python I was a self taught SQL user with advanced skills. It attempt to find the best fit line, which predicts the output more accurately. The ultimate aim of a decision tree is to reduce the entropy (randomness) in the data. The hypothesis for a normal equation goes like this -. We can then use the algorithm to identify the most likely class a target variable will probably fall into. Types of Classification - Binary Classification, Multi-Class Classification, and Multi-Label Classification. You will receive an in-depth look at Machine Learning topics such as working with real-time data, developing supervised and unsupervised learning algorithms, Regression, Classification, and time series modeling. In most cases, those classes are Yes or No. Thus, there are just two classes, and they are mutually exclusive. Simplilearn also offers other Artificial Intelligence and Machine Learning related courses, such as the Artificial Intelligence Engineer Masters course and the Deep Learning Course with Keras and TensorFlow Certification Training. The output variable has to be a discrete value. It is predominant in every industry sector as it empowers various organizations with innovative solutions to automate and increase the efficacy of products by reducing human intervention. For instance, lets consider the housing prices of a locality are only dependent on the area. Sentiment analysis and text classification. The mapping consists of multiple powers of an independent variable, which makes the equation non-linear. Loss functions - Mean Squared Error, Mean Absolute Error, Root Mean Squared Error, and Huber Loss. X refers to the input data matrix, and Y is the matrix of labels. Classification algorithms solve classification problems like identifying spam e-mails, spotting cancer cells, and speech recognition. Machine Learning Career Guide: A complete playbook to becoming a Machine Learning Engineer, Data Classification: Overview, Types, and Examples, Understanding the Difference Between Linear vs. Logistic Regression, An Introduction to Logistic Regression in Python, Regression vs. Last but not least, the best way to develop a complete understanding of machine learning is by implementing projects. Access to a curated library of 250+ end-to-end industry projects with solution code, videos and tech support. As mentioned above, Regression analysis helps in the prediction of a continuous variable. Classification and Regression trees, collectively known as CART, describe decision tree algorithms employed in Classification and Regression learning tasks. However, one of the disadvantages is they dont support online learning, so you have to rebuild your tree when new examples come on. We can classify Machine Learning algorithms into two types: supervised and unsupervised. Classification and Regression, both being supervised algorithms, require labeled data for training. There are many independent variables, or multicollinearity exists in your data. *Lifetime access to high-quality, self-paced e-learning content. As a result, we dont code the logic for our program; instead, we want a machine to figure out logic from the data on its own. Multi-Label Classification: Lets consider an example of semantic tagging. For instance, for a news article based on government regulations on Covid-19, the information can be classified under Political, Law & Government, and Healthcare categories. If youre looking for a career that combines a challenge, job security, and excellent compensation, look no further than the exciting and rapidly growing field of Machine Learning. The error between predicted and actual values gets squared at each point to arrive at a Sum of Squared Errors, or SSE. You then arrive at the final output by averaging the probabilities. The classification algorithms task mapping the input value of x with the discrete output variable of y. }, Post Graduate Program in AI and Machine Learning. That is to say, how would you feedback yourself?. Access Data Science and Machine Learning Project Code Examples. The particular case of credit scoring or fraud detection. It is similar to multiple linear regression, but it fits a non-linear curve between the value of x and corresponding conditional values of y. For example, decision-making trees are a supervised Machine Learning algorithm. If the training data showed that 85 percent of men liked a specific movie, the data is split at that point, and gender becomes a top node in the tree. Every week we sharetrending articlesandtoolsin our newsletter. If you could imagine the probability of the outcome of a task done for the first timeLets say the job is to learn to ride a car. To enumerate, the main difference between them is that the output variable in the regression is numerical (or continuous) whereas that for classification is categorical (or discrete). Simplilearn is one of the worlds leading providers of online training for Digital Marketing, Cloud Computing, Project Management, Data Science, IT, Software Development, and many other emerging technologies. Few of the examples where linear regression is used are: Apparently, there are a lot of advantages to this algorithmintegration of more features with a nice interpretation facility, easy updating facility to annex new data.
This SSE gets compared across all variables, and the point or variable with the lowest SSE becomes the split point, and the process continues recursively. Most importantly, Naive Bayes is a right choice when CPU and memory resources are a limiting factor. Regression estimates the relationship between the target and the independent variable. Decision Tree is a supervised learning algorithm which can be used for solving both classification and regression problems. PMP, PMI, PMBOK, CAPM, PgMP, PfMP, ACP, PBA, RMP, SP, and OPM3 are registered marks of the Project Management Institute, Inc. JavaTpoint offers too many high quality services. Get FREE Access to Machine Learning Example Codes for Data Cleaning, Data Munging, and Data Visualization. The categorial dependent variable assumes only one of two possible, mutually exclusive values. "publisher": { Otherwise, MSE is a better choice. "headline": "A-Z Guide to Text Summarization in Python for Beginners", Other evaluation metrics for classification are - precision, recall, and f1-score. "@type": "Organization", These algorithms majorly fall into two categories - supervised algorithms and unsupervised algorithms. A Regression tree describes an algorithm that takes ordered values with continuous values and predicts the value. Geekflare is supported by our audience. However, you may have cases where you need a prediction that considers multiple variables, such as Which of these four promotions will people probably sign up for? In this case, the categorical dependent variable has multiple values. This is done to reduce the chances of getting similar learning and predictions from every model.
The Random Forest regression is an ensemble learning method which combines multiple decision trees and predicts the final output based on the average of each tree output. Regression algorithms solve regression problems such as house price predictions and weather predictions. Once the entropy is calculated, the next step is to identify whether the entropy of a particular node has decreased compared to the parent node. SVR attempts to perform a linear regression-like algorithm with a non-linear mapping function in a high dimensional space. Decision tree algorithms are if-else statements used to predict a result based on the available data. It tries to measure the difference in entropy (randomness) between the predicted class and the actual class. Some example algorithms - Logistic Regression, Support Vector Machine, Decision Tree, and Random Forest. It uses non-linear kernel functions, like polynomials, to find an optimal solution for non-linear models. Consider the below image: Random forest is one of the most powerful supervised learning algorithms which is capable of performing regression as well as classification tasks. This loss focuses on penalizing incorrect classifications. It is majorly used in Support Vector Machines. So, in such a problem, multiple independent parameters linearly affect the dependent parameter (rating of a restaurant).
This process is possible by enlarging feature variable space by employing special functions known as kernels. There are two strategies to do this - Gradient Descent and Normal Equation. In addition, you will learn how to use Python to draw predictions from data. The output of a regression model is a continuous variable. i) Gradient Descent: The gradient descent rule is used to continuously update and optimize the values of and to reach the local minima. Once the parameters and are obtained, the mapping function of linear regression will be complete and can be used to predict the output of unseen inputs. Therefore, the regression prediction problems are usually quantities or sizes. It purely depends on the number of parameters indulged and the scenario under consideration. Types of Regression - Simple Linear Regression, Multiple Linear Regression, and Polynomial Regression. For instance, you could design a regression model with more features or polynomial terms and interaction terms. Below is how the random forest algorithm works -. Here are some of the tools and services to help your business grow. Simplilearn can help you get into this fantastic field thanks to its Machine Learning Certification course. Mathematically, information gain is represented as. Since linear regression is not a good choice for multiple outliers, logistic regression can accommodate such scenarios. The idea for classification is to find the best decision boundary to segregate the samples into discrete categories. Its objective function looks like: Support Vector Regression (SVR) is an extension of SVM algorithm to incorporate the continuous nature of values. Artificial Intelligence, Machine Learning Application in Defense/Military, How can Machine Learning be used with Blockchain, Prerequisites to Learn Artificial Intelligence and Machine Learning, List of Machine Learning Companies in India, Probability and Statistics Books for Machine Learning, Machine Learning and Data Science Certification, Machine Learning Model with Teachable Machine, How Machine Learning is used by Famous Companies, Deploy a Machine Learning Model using Streamlit Library, Different Types of Methods for Clustering Algorithms in ML, Exploitation and Exploration in Machine Learning, Data Augmentation: A Tactic to Improve the Performance of ML, Difference Between Coding in Data Science and Machine Learning, Impact of Deep Learning on Personalization, Major Business Applications of Convolutional Neural Network, Predictive Maintenance Using Machine Learning, Train and Test datasets in Machine Learning, Prediction of rain using temperature and other factors.