Missed GT Error (Missed) corresponds to all undetected ground truth (false negatives) not already covered by classification or localization error. This paper proposes a simple and scalable detection algorithm that improves mean average precision (mAP) by more than 30% relative to the previous best result on VOC 2012 -- achieving a mAP of 53.3%. The BigDetection dataset has 600 object categories and contains over 3.4M training images with 36M bounding boxes and is much larger in multiple dimensions than previous benchmarks, which offers both opportunities and challenges. Importantly, our framework is applicable across datasets and can be applied directly to output prediction files without required knowledge of the underlying prediction system. It is found that models generate boxes on empty regions and that context is more important for detecting small objects than larger ones and that classification error explains the largest fraction of errors and weighs more than localization and duplicate errors. the model has detected a part of the background. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation, Empirical Upper Bound in Object Detection and More, LVIS: A Dataset for Large Vocabulary Instance Segmentation, Scale-Aware Trident Networks for Object Detection, We introduce TIDE, a framework and associated toolbox for analyzing the sources of error in object detection and instance segmentation algorithms. What is holding back convnets for detection? For questions about our paper or code, make an issue in this github or contact Daniel Bolya. The approach, named SSD, discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location, which makes SSD easy to train and straightforward to integrate into systems that require a detection component. This work shows that only a very small fraction of features within a groundtruth bounding box are responsible for a teachers high detection performance, and proposes Prediction-Guided Distillation (PGD), which focuses distillation on these key predictive regions of the teacher and yields considerable gains in performance over many existing KD baselines. This paper proposes to address the extreme foreground-background class imbalance encountered during training of dense detectors by reshaping the standard cross entropy loss such that it down-weights the loss assigned to well-classified examples, and develops a novel Focal Loss, which focuses training on a sparse set of hard examples and prevents the vast number of easy negatives from overwhelming the detector during training. 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Graz University of Technology, Graz, Austria, University of Freiburg, Freiburg im Breisgau, Germany, University of North Carolina at Chapel Hill, Chapel Hill, NC, USA, https://dl.acm.org/doi/10.1007/978-3-030-58580-8_33.
Importantly, our framework is applicable across datasets and can be applied directly to output prediction files without required knowledge of the underlying prediction system.
Localization Error (Loc) corresponds to an incorrectly localized prediction ( $t{b} \leq IoU{max} \leq t_{f]$ ) and correctly classified. This work introduces LVIS (pronounced el-vis): a new dataset for Large Vocabulary Instance Segmentation, which has a long tail of categories with few training samples due to the Zipfian distribution of categories in natural images. More details and documentation on how to write your own database drivers coming soon! 
View 4 excerpts, cites background and methods. Semantic Scholar is a free, AI-powered research tool for scientific literature, based at the Allen Institute for AI.  View 2 excerpts, references methods and background. https://doi.org/10.1007/978-3-030-58580-8_33, All Holdings within the ACM Digital Library.
View 2 excerpts, references methods and background. https://doi.org/10.1007/978-3-030-58580-8_33, All Holdings within the ACM Digital Library.  TIDE: A General Toolbox for Identifying Object Detection Errors, Microsoft COCO: common objects in context. 2014 IEEE Conference on Computer Vision and Pattern Recognition. By clicking accept or continuing to use the site, you agree to the terms outlined in our. We introduce TIDE, a framework and associated toolbox ( https://dbolya.github.io/tide/) for analyzing the sources of error in object detection and instance segmentation algorithms. How good are detection proposals, really?
TIDE: A General Toolbox for Identifying Object Detection Errors, Microsoft COCO: common objects in context. 2014 IEEE Conference on Computer Vision and Pattern Recognition. By clicking accept or continuing to use the site, you agree to the terms outlined in our. We introduce TIDE, a framework and associated toolbox ( https://dbolya.github.io/tide/) for analyzing the sources of error in object detection and instance segmentation algorithms. How good are detection proposals, really?
Import annotation from other Dataset version. What is important is that our framework is applicable across data sets and can be directly applied to the output prediction file without needing to understand the underlying prediction system. Check if you have access through your login credentials or your institution to get full access on this article. Reference: https://cloud.tencent.com/developer/article/1738791 [Target Detection] Open Source | TIDE: Target Detection Error Analysis Tool-Cloud + Community-Tencent Cloud, [Target Detection] Open Source | TIDE: Target Detection Error Analysis Tool. The UniversalScale object detection Benchmark (USB) is introduced, and a fast and accurate object detectors called UniverseNets is designed, which surpassed all baselines on USB and achieved state-of-the-art results on existing benchmarks. To manage your alert preferences, click on the button below. View 3 excerpts, cites background and methods. TIDE: A General Toolbox for Identifying Object Detection Errors. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Paper address: http://arxiv.org/pdf/2008.08115v2.pdf, Paper Title: TIDE: A General Toolbox for Identifying Object Detection Errors. Classification and localization error (Both) corresponds to an incorrectly localized and incorrectly classified prediction. We present a new dataset with the goal of advancing the state-of-the-art in object recognition by placing the question of object recognition in the context of the broader question of scene. It is interesting to understand where the recurrent errors of an object detection model come from so that its improvement is targeted. We show that such a representation is critical for drawing accurate, comprehensive conclusions through in-depth analysis across 4 datasets and 7 recognition models. We. Check out our ECCV 2020 short video for an explanation of what TIDE can do: TIDE is available as a python package for python 3.6+ as tidecv. Background Error (Bkgd) corresponds to a prediction that does not match any ground truth ($IoU{max} \leq t{b}$), i.e. This article introduces TIDE, a framework and associated toolbox for analyzing the sources of errors in target detection and instance segmentation algorithms. This work quantifies the impact introduced by each sub-task and found the localization error is the vital factor in restricting monocular 3D detection, and investigates the underlying reasons behind localization errors. A detailed comparative analysis of LRP with AP and PQ is provided, and nearly 100 state-of-the-art visual detectors from seven visual detection tasks are used to empirically show that LRP provides richer and more discriminating information than its counterparts. A diagnostic tool for analyzing the sources of detection errors in video relation detection and examines different factors of inuence on the performance in a false negative analysis, including relation length, number of subject/ object/predicate instances, and subject/object size. The currently supported datasets are COCO, LVIS, Pascal, and Cityscapes. A conceptually novel, efcient, and fully convolutional framework for real-time instance segmentation, based on bipartite matching, that can predict objects in a one-to-one style, thus avoiding non-maximum suppression (NMS) in post-processing. Thus, our framework can be used as a drop-in replacement for the standard mAP computation while providing a comprehensive analysis of each models strengths and weaknesses. Georgia Institute of Technology, Atlanta, USA. The thresholds are set as follows : t{b} = 0.1 and t{f} = 0.5. TIDE is meant as a drop-in replacement for the COCO Evaluation toolkit, and getting started is easy: This prints evaluation summary tables to the console: And a summary plot for your models errors: Check out the example notebook for more details. This work presents a conceptually simple, flexible, and general framework for object instance segmentation, which extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. We divide errors into six types, and the most important thing is that we first introduced a technique to measure the impact of each error while isolating the impact of the error on the overall performance. 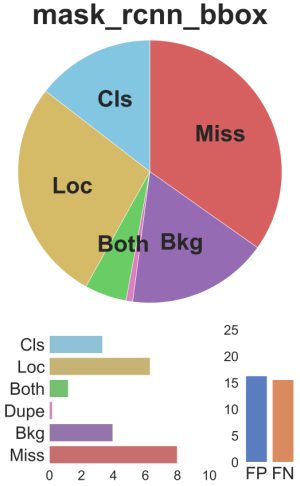 Thus, our framework can be used as a drop-in replacement for the standard mAP computation while providing a comprehensive analysis of each model's strengths and weaknesses. Diagnosing Errors in Video Relation Detectors, Sensitivity of Average Precision to Bounding Box Perturbations, BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training, Complementary datasets to COCO for object detection, USB: Universal-Scale Object Detection Benchmark, Logit Normalization for Long-tail Object Detection, Delving into Localization Errors for Monocular 3D Object Detection, Sparse Instance Activation for Real-Time Instance Segmentation, One Metric to Measure them All: Localisation Recall Precision (LRP) for Evaluating Visual Detection Tasks, Prediction-Guided Distillation for Dense Object Detection, Microsoft COCO: Common Objects in Context. We use cookies to ensure that we give you the best experience on our website. Six types of recurring errors are defined using, for each prediction, thresholds on the IoU with the ground truth and the predicted class : Classification Error (Cls) corresponds to a correctly localized prediction ($IoU{max} \geq t{f]$ ) but incorrectly classified.
Thus, our framework can be used as a drop-in replacement for the standard mAP computation while providing a comprehensive analysis of each model's strengths and weaknesses. Diagnosing Errors in Video Relation Detectors, Sensitivity of Average Precision to Bounding Box Perturbations, BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training, Complementary datasets to COCO for object detection, USB: Universal-Scale Object Detection Benchmark, Logit Normalization for Long-tail Object Detection, Delving into Localization Errors for Monocular 3D Object Detection, Sparse Instance Activation for Real-Time Instance Segmentation, One Metric to Measure them All: Localisation Recall Precision (LRP) for Evaluating Visual Detection Tasks, Prediction-Guided Distillation for Dense Object Detection, Microsoft COCO: Common Objects in Context. We use cookies to ensure that we give you the best experience on our website. Six types of recurring errors are defined using, for each prediction, thresholds on the IoU with the ground truth and the predicted class : Classification Error (Cls) corresponds to a correctly localized prediction ($IoU{max} \geq t{f]$ ) but incorrectly classified.
This work quantifies the sensitivity of AP to bounding box perturbations and shows that AP is very sensitive to small translations, explaining why achieving higher mAP becomes increasingly harder as models get better. A novel Trident Network (TridentNet) aiming to generate scale-specic feature maps with a uniform representational power is proposed and a parallel multi-branch architecture in which each branch shares the same transformation parameters but with different receptive elds is constructed. # Summarize the results as tables in the console. Specify a folder and it'll output a png to that folder. An in depth analysis of ten object proposal methods along with four baselines regarding ground truth annotation recall (on Pascal VOC 2007 and ImageNet 2013), repeatability, and impact on DPM detector performance are provided. Duplicate Detection Error (Dupe) corresponds to the situation where the prediction is correctly localized and correctly classified but another correctly localized and correctly classified prediction exists with a higher confidence level. The ACM Digital Library is published by the Association for Computing Machinery.
Two complementary datasets to COCO are introduced and some models are evaluated, used to test the generalization ability of object detectors and the source of errors are evaluated. IEEE transactions on pattern analysis and machine intelligence.
This alert has been successfully added and will be sent to: You will be notified whenever a record that you have chosen has been cited. This paper proposes Logit Normalization (LogN), a simple technique to self-calibrate the classified logits of detectors in a similar way to batch normalization, which can serve as a strong baseline for long-tail object detection and is expected to inspire future research in this field. # Show a summary figure. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Copyright 2022 ACM, Inc. Computer Vision ECCV 2020: 16th European Conference, Glasgow, UK, August 2328, 2020, Proceedings, Part III. When providing a comprehensive analysis of the advantages and disadvantages of each model, our framework can replace standard mAP calculations. This paper shows how to analyze the influences of object characteristics on detection performance and the frequency and impact of different types of false positives, and shows that sensitivity to size, localization error, and confusion with similar objects are the most impactful forms of error. Note that I may not respond to emails, so github issues are your best bet. This is the code for our paper: TIDE: A General Toolbox for Identifying Object Detection Errors (ArXiv) [ECCV2020 Spotlight]. View 4 excerpts, references background and methods. Through in-depth analysis of 4 data sets and 7 recognition models, it is found that the framework of this paper can draw accurate and comprehensive conclusions. If you use TIDE in your project, please cite. To install, simply install it with pip: The current version is v1.0.1 (changelog). We segment errors into six types and, crucially, are the first to introduce a technique for measuring the contribution of each error in a way that isolates its effect on overall performance. Since a false positive with a lower score has less effect on overall performance than one with a higher score, the errors are weighted so that they can be compared. View 5 excerpts, references methods and background, 2017 IEEE International Conference on Computer Vision (ICCV).
An easy-to-use, general toolbox to compute and evaluate the effect of object detection and instance segmentation on overall performance.